Die Wikimedia Foundation will eine Wissensplattform jenseits von Artikeln schaffen. Bots und ähnliche Techniken sollen dabei helfen. Doch wo ist in Zukunft der Platz für menschliche Autoren?
Während Wikipedia seit Jahren in vielen Bereichen stagniert, nimmt das Schwesterprojekt Wikidata Fahrt auf. Zum fünften Jahrestag konnte die Datenplattform Einträge zu 37 Millionen verschiedenen Datenobjekten verzeichnen – fast jeder dritte Beitrag zu Wikimedia-Projekten ist ein Beitrag zu Wikidata. Dabei ist das Projekt in der Öffentlichkeit kaum bekannt.
Dies könnte sich ändern. So skizziert die Wikimedia Foundation in einem Strategiepapier eine Zukunft, in der Wikipedia nur noch Teil des Gesamtprojekts sein soll. „Im Jahr 2030 wird Wikimedia das Fundament im Netzwerk des freien Wissens sein und jeder, der unsere Vision unterstützt, soll sich uns anschließen können.“ In dieser Zukunft bauen nicht nur menschliche Autoren das Fundament, sondern auch Maschinen: „Unser gemeinsamer Erfolg wird durch Menschen ermöglicht und durch Technologie unterstützt. So beschreiben und verstehen wir gemeinsam unsere Welt.“
Jenseits von Bücherwissen
Sprich: Die Organisation hinter der Wikipedia will neue Techniken erforschen, mit denen sie Wissen archivieren und für Menschen aufbereiten kann. Sei es in Form von Wikipedia-Artikeln oder einer Frage-Antwort-Maschine, die zielgenau Informationen heraussucht, die der Nutzer gerade braucht.
Ein Stützpfeiler für dieses Ziel ist Wikidata. Das Schwesterprojekt der Wikipedia erfasst das Weltwissen nicht in Artikelform, sondern in einer Datenbankstruktur. Statt beispielsweise einen langen Artikel über das Leben und Werk des Schriftstellers Douglas Adams zu verfassen, werden in Wikidata dem Objekt Douglas Adams – oder auch: Q42 – eine Vielzahl von Aussagen zugewiesen: zum Beispiel sein Geburts- und Sterbedatum, die von ihm verfassten Bücher oder Wikipedia-Ausgaben und öffentliche Datenbanken, in denen man weitere Informationen über diesen Schriftsteller finden kann.
Die Datensammlung offenbart auch Defizite in der bisherigen Wikipedia-Arbeit. Datenabgleiche zeigten, dass beispielsweise Beiträge über weibliche Personen der Zeitgeschichte in der Wikipedia unterrepräsentiert sind. Eine eigene Projektgruppe auf Wikidata hat sich zusammengefunden, um diese Unstimmigkeiten zu identifizieren und wirksam gegenzuarbeiten, indem die Teilnehmer gezielt Artikel und Wikidata-Einträge über Frauen anlegen und pflegen. So soll vermieden werden, dass sich der menschliche BiasBias In der KI bezieht sich Bias auf Verzerrungen in Modellen oder Datensätzen. Es gibt zwei Arten: Ethischer Bias: systematische Voreingenommenheit, die zu unfairen oder diskriminierenden Ergebnissen führt, basierend auf Faktoren wie Geschlecht, Ethnie oder Alter. Mathematischer Bias: eine technische Abweichung in statistischen Modellen, die zu Ungenauigkeiten führen kann, aber nicht notwendigerweise ethische Probleme verursacht. in die Datenstruktur der Wikidata und weiterer Plattformen einfrisst.
Wenn ein Sprachassistent wie Amazons Alexa oder Google Home eine allgemeine Frage beantwortet, kommt die Information schon heute mit großer Wahrscheinlichkeit aus Wikipedia. Dank Wikidata wird das Wissen der Wikipedia künftig an immer mehr Stellen auftauchen. Denn die Datenbank ist direkt maschinell auslesbar, während der Wissenssteinbruch Wikipedia mit verschiedenen Texterfassungstechniken ausgewertet werden muss.
„Der Einfluss von Wikidata ist vielleicht sogar außerhalb der Wikimedia-Plattform vielleicht sogar signifikanter als innerhalb“, schreibt Autor und Forscher Andrew Lih – so verknüpfen bereits heute Nationalbibliotheken und Museen ihre Kataloge mit Wikidata. Vorteil für die Institutionen: Ihre eigenen Informationen werden so der Öffentlichkeit zugänglich gemacht und sie selbst können ihren Besuchern mehr Informationen bieten. Gleichzeitig dient der Datenabgleich der Korrektur: Wenn ein Autor oder Künstler nicht auf Wikidata gefunden werden kann, ist der Name im eigenen Katalog vielleicht falsch geschrieben. Wikidata wird so zur zentralen SchnittstelleAPI (Application Programming Interface) Eine Schnittstelle, die es verschiedenen Softwareanwendungen ermöglicht, miteinander zu kommunizieren und Daten auszutauschen. APIs definieren, wie Anfragen und Antworten zwischen Programmen strukturiert sein sollten. für zahlreiche Datenbanken, die verschiedenste Bereiche des Weltwissens abbilden.
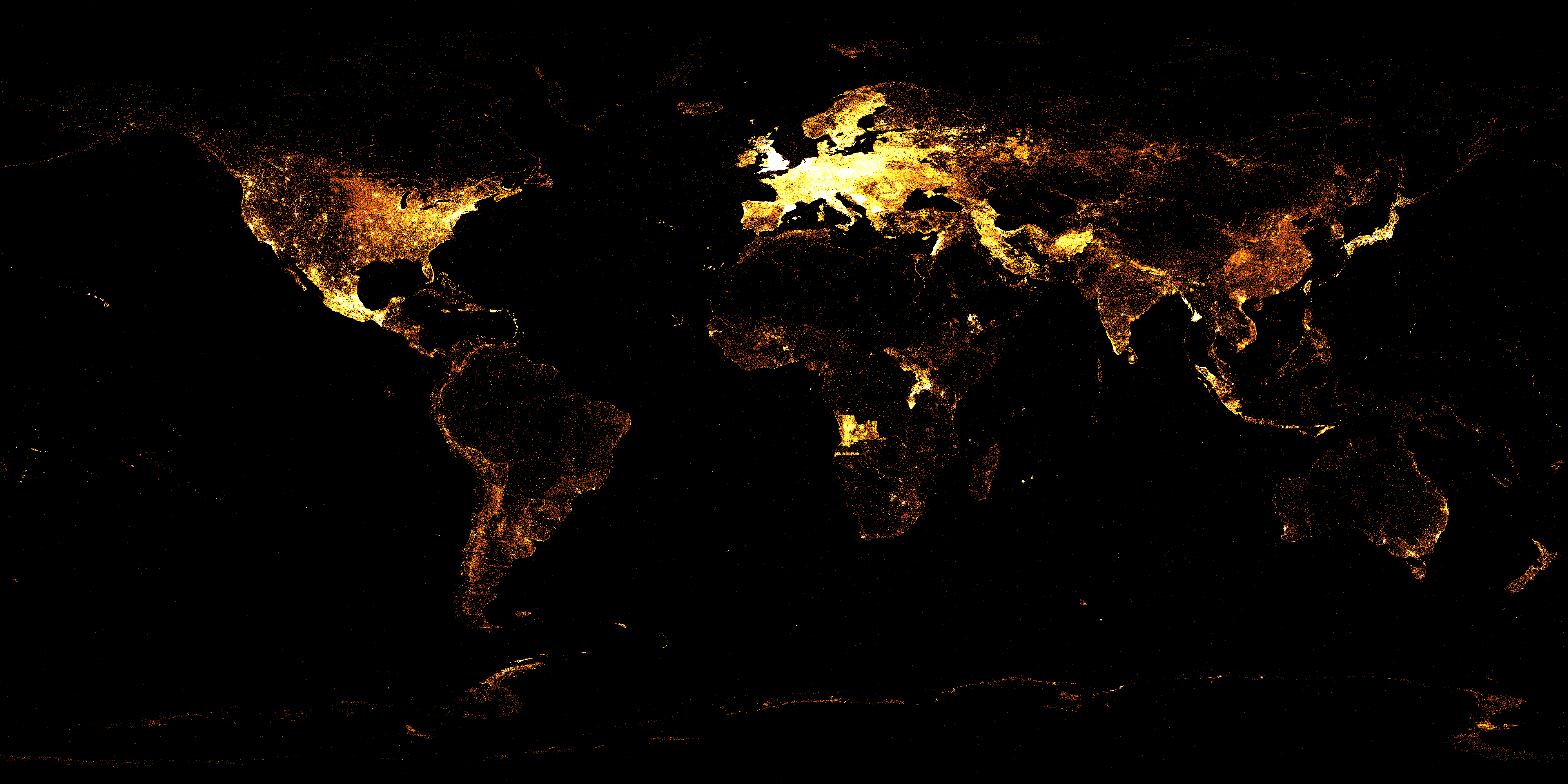
Die grafische Aufbereitung der Wikidata-Einträge zeigt, welche Gegenden der Welt bereits gut erfasst sind und wo noch schwarze Flecken überwiegen. (Quelle: Wikimedia.org)
Bots schreiben die Cebuano-Wikipedia voll
Wikidata ist nicht nur maschinenlesbar, Bots übernehmen auch einen Großteil der Schreibarbeit auf der Plattform. Wenn zum Beispiel eine geographische Datenbank oder ein bibliographischer Katalog mit mehreren Tausend oder gar Millionen Einträgen in Wikidata importiert werden muss, suchen Algorithmen die entsprechenden Wikidata-Objekte und fügen die jeweiligen Informationen eigenständig hinzu. Menschen müssen jedoch weiterhin die Qualitätskontrolle übernehmen und als Schiedsrichter tätig werden, wenn die gefundenen Daten nicht zusammenpassen.
Die Bot-Wikipedia
Im Prinzip könnten Bots so auch einen Großteil der Arbeit in Wikipedia-Ausgaben erledigen, die keine so große Community haben wie die englische oder deutsche Ausgabe. Wenn ein Wikidata-Objekt mit genug Statements angereichert ist, kann ein Bot daraus einen Text erzeugen, der zumindest wie ein Wikipedia-Artikel aussieht.
Eine von Bots geschriebene Wikipedia ist keine Zukunftsmusik. Während die deutsche und englische Sprachausgabe jeweils auf zehn Prozent Beiträge von Bots kommen, ist der Anteil gerade in kleineren Sprachausgaben wesentlich höher. Spitzenreiter ist die Wikipedia-Ausgabe in der philippinischen Sprache Cebuano, die auf eine Botaktivität von nahezu hundert Prozent kommt.
Dank dem extensiven Einsatz von Bots konnte die cebuanosprachige Wikipedia die deutsche Ausgabe bei der Anzahl der Artikel überholen. Mit über 5 Millionen Artikeln ist sie nun die zweitgrößte Ausgabe weltweit.
Verantwortlich ist insbesondere der von dem schwedischen Wikipedia-Autoren Lars Sverker Johansson programmierte “Lsjbot”, der seit Jahren Tag für Tag tausende Artikel basierend auf Datenbankeinträgen aller Art verfasst. Dank seiner Aktivität finden sich in dieser Wikipedia-Ausgabe Miniartikel zu selbst den kleinsten Orten in Deutschland und den unbekanntesten Tierarten. Der Effekt: Die cebuanosprachige Wikipedia ist heute formell mit über fünf Millionen Artikeln die zweitgrößte Ausgabe weltweit. Ob die nach einfachen Schablonen erstellten Texte aber tatsächlich Wissen repräsentieren oder dem Projekt insgesamt nützen, ist in der Wikipedia-Community umstritten.
![]()
Das Profilbild des “Lsjbot”
Streit um im Akkord schreibende Bots
Befürworter von automatisch erzeugten Artikeln argumentieren, dass die zusammengetragenen Informationen immer einen Wert haben, den man den jeweiligen Lesern der Wikipedia-Ausgaben zur Verfügung stellen sollte. Zudem geht diese Denkschule davon aus, dass ein bereits angelegter Artikel Leser dazu einladen kann, selbst zu Autoren zu werden.
Kritiker dieser Entwicklung führen an, dass Wissen immer einen Kontext braucht, der besser von der jeweiligen Wikipedia-Community erarbeitet wird. So ist es in den meisten Wikipedia-Communities verpönt, einfach einen Artikel aus einer anderen Wikipedia-Ausgabe in die eigene Landessprache zu übersetzen. Wikipedia gilt in der Wikipedia selbst nicht als hinreichende Quelle für eine Information. Gleichzeitig befürchten die Kritiker, dass automatisch erstellte Artikelgerüste potenzielle Autoren demotivieren. Wer schon zu jedem möglichen Thema einen Artikel findet, hat wenig Anlass, selbst einen komplett neuen zu beginnen.
Bots sollen menschliche Autoren motivieren
Die Wikimedia Foundation verhält sich in dieser Frage neutral. Welche Bots eine Community einsetzen will, müssen die Mitglieder selbst entscheiden. Die Organisation sucht einen Mittelweg: „Wir konzentrieren uns darauf, Techniken zu entwickeln, die den menschlichen Autoren in der Wikipedia Unterstützung bieten”, erklärt Aaron Halfaker, der für die Wikimedia Foundation unter anderem zur Anwendung von neuronalen Netzwerken forscht.
So hat die Wikimedia Foundation eine Schnittstelle geschaffen, die Autoren Tipps gibt, wo sie ihre Arbeit am nutzbringendsten einsetzen können. Das neuronale Netzwerk, das den Vandalismus bekämpfenden „ClouBot NG“ mit Hinweisen auf Vandalismus versorgt, bewertet auch die Qualität von Artikeln, um so die drängendsten Baustellen in der Wikipedia zu identifizieren. Statt nur Autoren automatisch abzulehnen, haben die Algorithmen auch die Aufgabe, Autoren zu besserer Arbeit zu motivieren.
Neuronales NetzNeuronale Netzwerke Ein Modell der Künstlichen Intelligenz, das die Arbeitsweise des menschlichen Gehirns nachahmt. Es besteht aus vielen miteinander verbundenen „Neuronen“ oder Knotenpunkten, die in Schichten angeordnet sind. Diese Netzwerke lernen durch Anpassung der Verbindungen zwischen den Neuronen, um Muster in Daten zu erkennen und daraus Vorhersagen oder Entscheidungen zu treffen. ahmt menschliche Wikipedia-Autoren nach
Eine andere Kompromisslösung ist der sogenannte „ArticlePlaceholder“, der besonders in kleineren Wikipedia-Ausgaben aktiviert wird. Sucht ein Leser in Tirana zum Beispiel nach einem bestimmten Thema, das noch nicht in der albanischen Wikipedia, dafür aber in anderen Ausgaben vorhanden ist, wird ein tabellarischer Informationsstand aus Wikidata generiert. So bekommt er die für ihn relevanten Informationen geliefert, ohne dieses Produkt mit einem von Menschen verfassten Artikel zu verwechseln.
Manchen ist das aber nicht genug. So arbeitet ein kleines Forscherteam an den Universitäten von Southampton und Lyon daran, die Wikidata-Informationen mithilfe eines neuronalen Netzwerkes in natürliche Sprache zu übersetzen. Statt nur mit festgelegten Schablonen wie „Lsjbot“ zu arbeiten, bindet das neue Projekt die bisherige Arbeit der menschlichen Autoren ein.
„Unser Modell lernt von den Daten, die in Wikidata erfasst sind und den entsprechenden Artikeln in der Wikipedia, wie man eine einführende Zusammenfassung schreibt“, erklärt Lucie-Aimée Kaffee gegenüber blogs.bertelsmann-stiftung.de/algorithmenethik. Bei den ersten Experimenten in Esperanto und Arabisch habe sich diese Methode im Vergleich zur maschinellen Übersetzung der englischen Artikeltexte als besser erwiesen
„Nicht in unserer Lebenszeit“
Die Notwendigkeit für dieses Projekt begründet Kaffee mit dem langsamen Fortschreiten beim Ausbau von Sprachversionen: „Zum Beispiel existiert nur in der englischen, der deutschen und der russischen Wikipedia-Ausgabe ein Artikel über den elektronischen Aufenthaltstitel.” Dieser dient Ausländern in Deutschland und in der Europäischen Union zum Nachweis ihres Aufenthaltsrechts. In den Sprachen der größten Einwanderergruppen jedoch fehlten Informationen zu diesem Titel.
Halfaker zeigt sich skeptisch, dass die von dem Forscherteam erforschte Methode tatsächlich dazu taugt, vollwertige Artikel zu erstellen. „Aber ich glaube, dass es eine große Nische für die automatisierte Texterstellung gibt. Die Technik könnte eventuell menschlichen Autoren, die einen Artikel starten wollen, zur Hand gehen.“
Letztlich seien die Algorithmen jedoch überfordert, vollwertige Artikel zu erstellen, ist sich Halfaker sicher. „In unserer Lebenszeit werden Algorithmen die menschlichen Autoren in der Wikipedia nicht ersetzen”, erklärt der Wikimedia-Forscher.
Weitere Erkenntnisse zur Zusammenarbeit von Bots und menschlichen Autoren in der Wikipedia finden Sie in Teil 1 und Teil 2 unserer Serie. Über neue Beiträge in diesem Blog können Sie sich per RSS-Feed oder per E-Mail-Newsletter benachrichtigen lassen.

{kind=link}
Kommentar schreiben