Der Entwicklungsprozess von algorithmischen Entscheidungssystemen ist lang und eine große Anzahl unterschiedlicher Akteure ist daran beteiligt. Deshalb können an vielen Stellen Fehler passieren – die meisten lassen sich aber vermeiden oder beheben. Katharina Zweig beschreibt anschaulich, wie algorithmische Systeme derzeit entwickelt und eingesetzt werden, und zeigt Verantwortlichkeiten sowie potenzielle Fehlerquellen auf.
Wo algorithmische Systeme gebaut werden, sind viele Menschen involviert und verantwortlich: Wissenschaftler, Programmierer, Data Scientists sowie staatliche und wirtschaftliche Institutionen oder NGOs als Datensammler, Anwender oder Überprüfer. Sie alle treffen Entscheidungen im Prozess, den ein algorithmisches System von seiner Entwicklung bis zur Evaluation durchläuft. Diesen Prozess beschreibt das Arbeitspapier „Wo Maschinen irren können“. Es ordnet Verantwortlichkeiten zu, um einer Diffusion der Verantwortung in komplexen Systemen („Mathwashing“) entgegenzuwirken.
In den fünf Prozess-Phasen kann vieles schiefgehen. Fehler können in allen fünf auftreten – mit unterschiedlich weitreichenden Auswirkungen. In der ersten Phase des Algorithmendesigns werden Fehler meist schnell entdeckt und sind daher selten. Besonders häufig tauchen Fehler in der vierten Phase auf, der Einbettung in die gesellschaftliche Praxis. Hier interagieren Anwender mit dem algorithmischen System und können das Ergebnis einer Prognose zum Beispiel falsch interpretieren. Das kann folgenschwer sein, etwa wenn es um die Rückfälligkeitsprognose von Straftätern geht. Auch in der fünften Phase, der Re-Evaluation des Entscheidungssystems, können Fehler etwa Diskriminierungen zur Folge haben. Das kann beispielsweise passieren, wenn das System Feedback erhält, das sich selbst verstärkt. Ein Beispiel: Beim Predicitive Policing fährt die Polizei auf Grundlage der Systemprognosen vermehrt Streife in einem Viertel, dadurch entdeckt sie dort auch mehr Kleinkriminalität und es kommt zu mehr Festnahmen. Das System lernt daraus, dass es dort mehr Kriminalität gibt und empfiehlt dort noch mehr Kontrollen.
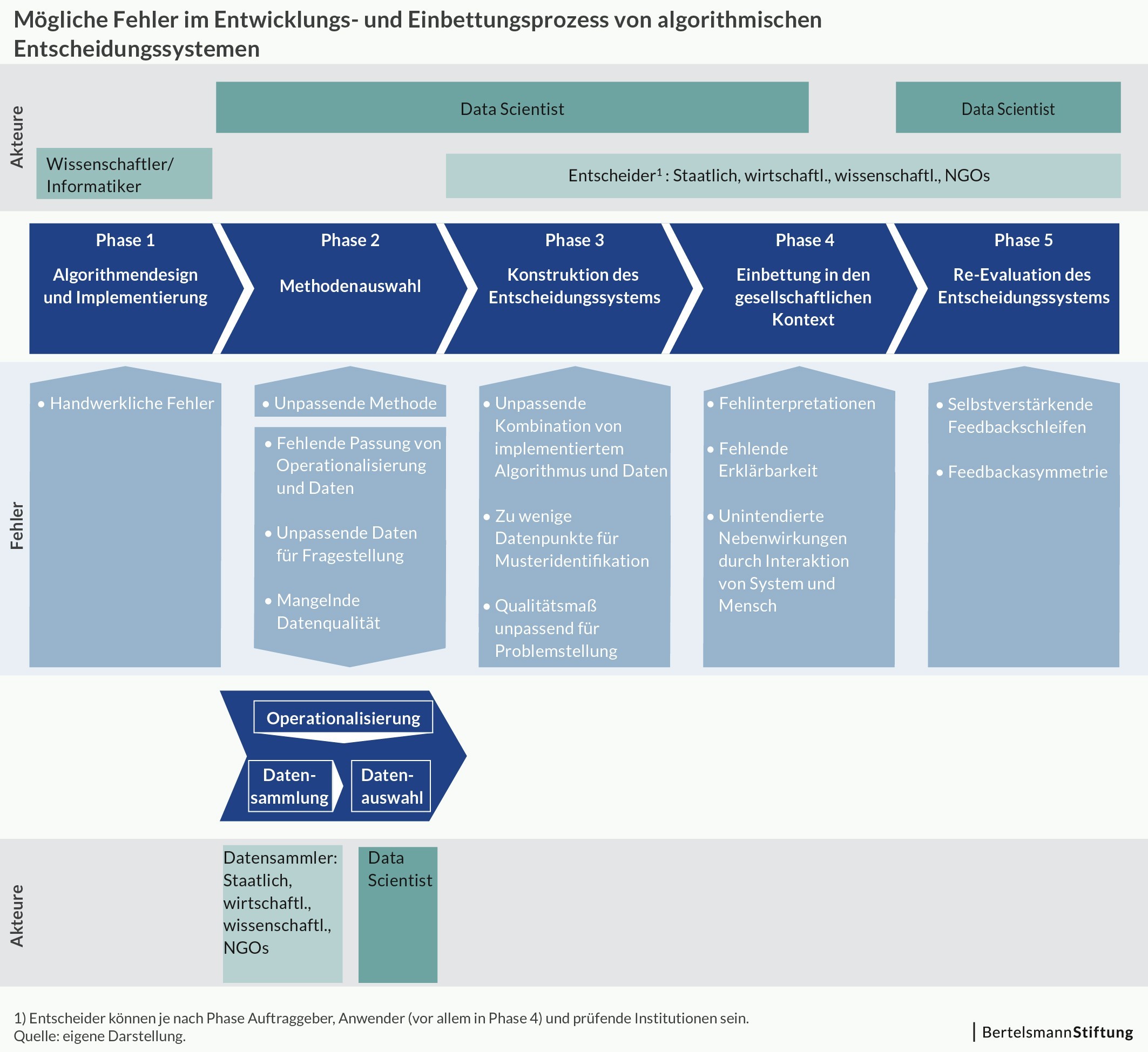
Bei der Beschreibung derartiger Fehler bleibt das Arbeitspapier nicht stehen. Es skizziert darüber hinaus lösungsorientiert Instrumente und Maßnahmen, um ihnen zu begegnen. Fehlinterpretationen von Anwendern können beispielsweise vermieden werden, wenn diese Trainings erhalten und es „Beipackzettel“ für algorithmische Systeme gibt, die deren Ziel, Funktionsweise und mögliche Nebenwirkungen erklären. Fehler wie selbstverstärkendes Feedback können durch externe Beforschung von Entscheidungssystemen aufgedeckt werden. Nicht nur diese, die meisten der Fehler im Entwicklungsprozess algorithmischer Systeme lassen sich vermeiden oder beseitigen. Dazu braucht es aber eine Sensibilität für Fehler bei allen Beteiligten und eine aktive Gestaltung für eine höhere Nachvollziehbarkeit und Überprüfbarkeit des Prozesses.
Hier finden Sie das PDF zum Arbeitspapier “Wo Maschinen irren” mit Cover, das nicht unter eine CC-Lizenz fällt.
Wenn sie das Arbeitspapier weiterverwenden möchten, finden sie hier eine Version ohne Cover, die komplett CC-lizensiert ist.



Kommentar schreiben