Im vergangenen Jahr ist die Skepsis gegenüber Künstlicher Intelligenz (KI) zu Recht gestiegen. Wenn all diese Technologien ohne strenge ethische Rahmenbedingungen oder ohne Berücksichtigung der öffentlichen oder mindestens betroffenen Interessen angewendet werden, fürchten viele individuelle und gesellschaftliche Nachteile und sogar die Bedrohung menschlichen Lebens. Anlass für diese Sorge könnte unter vielen Beispielen etwa die Erklärung des Fahrdienstes Uber sein, der unlängst seine selbstfahrenden Autos wieder zurück auf die Strasse entließ, nachdem im März 2018 ein Fahrzeug der Firma in Arizona einen tödlichen Unfall verursacht hatte.
Aber ist es eine angemessene Reaktion auf diese Beispiele und jene gesellschaftliche Stimmung, wenn die Integration von Ethik in KI (Technologien und Anwendungen), unabhängig davon, was genau darunter gefasst wird, als einer der sechs wichtigsten Trends der KI für 2019 ausgerufen wird?Wenn der hiesige Zeitgeist mit der Gründung des Forschungsinstituts für Ethik in KI mit großem Drittmittelzuschuss von Facebook bedient wird?
Eine Antwort benötigt zunächst drei klärenden Bemerkungen:
-
-
- Der Skandal bei Unfällen mit „autonomen“ Fahrzeugen liegt nicht in der Maschine begründet, sondern in unserer Unverantwortlichkeit. Wir verfügen einerseits über sehr strikte Regeln für Medikamententests oder im Flugzeugverkehr, haben aber andererseits für selbstfahrende Autos keine oder kaum Regeln und lassen somit unausgereifte, noch ziemlich dumme KI / Technologie auf Menschen los.
- Mehr begriffliche Klarheit ist in Diskursen notwendig oder, wie es auch Angela Merkel in einer Diskussion mit Studenten der japanischen Elite-Universität Keio am 05. Februar forderte: Entmystifiziert KI. Wenn KI heutzutage und absehbar im Wesentlichen ein bloßes Tool (zur Datenauswertung) ist und wenn es nicht bloß um ethische Leitplanken für Zeilen von Codes gehen soll, was irgendwie trivial wäre, weil man Vermeidung von Leid, Integrität usw. immer von Entwicklern, Anwendern, etc. von Tools fordern kann, dann ist erst einmal unklar, worum es bei „Ethik in KI“ überhaupt gehen soll.
- Die Trennung zwischen Ursachenforschung, was einem beschreibenden Vorgang gleicht, und Fragen nach Schuld oder Verantwortung, was einer wertenden Aussage entspricht, ist essentiell für aufgeklärtere Debatten. Die Maschine mag zwar das Ereignis des Unfalls verursacht haben, aber wer ist zur Verantwortung zu ziehen: Die KI-Programmierer? Die KI-Firma? Die KI selbst?
-
Dieser Beitrag will Licht in den KI-Verständnisnebel bringen und dabei dreierlei leisten. Zunächst wird Angela Merkels Appell folgend etwas begriffliche Klärung und eine Abgrenzung von KI vs. verwandten Begriffen wie Machine LearningMachine Learning Ein Teilbereich der KI, bei dem Systeme aus Daten lernen und sich verbessern, ohne explizit programmiert zu werden. und Algorithmen vorgenommen. Sodann steht das sogenannte Deep Learning im Fokus, ein spezielles Machine-Learning-Verfahren, das unter anderem die Irish Times als die bedeutsamste Entwicklung und KI-Fähigkeit für dieses Jahr kürt, was man aber gleichzeitig angesichts der häufigen Trendwechsel in der KI-Welt nicht überbewerten sollte. Zweitens prüfen wir den Hype um Deep Learning und fragen drittens, wo wir heute mit dieser Technologie stehen, welche Trends sich abzeichnen und welche Anforderungen zu bedienen wären, bevor man von verantwortungsübernahmefähiger KI oder KI als moralischem Akteur sprechen sollte.
Babylonisches Sprachgewirr: Künstliche Intelligenz (KI) vs. Maschinelles LernenMachine Learning Ein Teilbereich der KI, bei dem Systeme aus Daten lernen und sich verbessern, ohne explizit programmiert zu werden. (ML) vs. Deep Learning (DL)
John McCarthy prägte 1956 den Begriff der KI. Er definierte sie als “die Wissenschaft und Technik der Herstellung intelligenter Maschinen”. Wenn das Feld der KI heute ziemlich breit und vage erscheint, dann vielleicht aus diesem Grund. Unter dieser Definition könnte die gesamte Software (respektive Hardware oder Roboter), die wir verwenden, als KI betrachtet werden, je nachdem, wie wir “intelligent” fassen.
Vielleicht nähern wir uns also den Begriffen KI, ML, DL aus einer anderen Richtung und fassen zunächst ihre zentrale Oberklasse in den Blick: Algorithmen. Algorithmen oder Programme bezeichnen eine Abfolge einzelner Anweisungen, mit denen Computer Probleme lösen. „KI“ umfasst eine spezielle Art von Algorithmen, nämlich solche, welche die Fähigkeit besitzen, selbständig, also ohne explizite Anweisungen zu lernen und in ebendiesem, wenn überhaupt, engeren Sinne intelligent sind. Und das ist am ehesten beim Maschinellen Lernen (ML) der Fall.
ML ist im Kern auf profane Statistik zurückzuführen, wobei Daten (als Trainingsdaten) sowie beschreibende Informationen, die sogenannten Metadaten, zunächst in ein bestimmtes Computerprogramm eingegeben werden. Ein Beispiel wären 100 Bilder von Autos mit den dazugehörigen Metadaten „Dieses Bild zeigt ein Auto“. Das Programm versucht dann durch stetiges Anpassen seiner Funktionsweise in den Daten Muster, Zusammenhänge und Gesetzmässigkeiten zu erkennen und kann schließlich auch bei Bildern, die es noch nicht „gesehen“ hat, mit einer statistischen Wahrscheinlichkeit voraussagen, dass es sich um ein Auto handelt. Oft spricht man von KI und meint schlicht ML: Daten werden erhoben, ein Computer wertet diese aus und trifft auf Basis seines Trainings Trefferwahrscheinlichkeiten oder gibt Prognosen für die Zukunft. Maschinen lernen durch endlose Wiederholung. Je mehr (hochwertige) Daten (da zum Beispiel aus verschiedenen Quellen) eingespeist werden, desto präziser wird die Vorhersage/Diagnose, weil die Software a posteriori lernt. Eine komplexe Variante des ML, die näher an unserem Verständnis von Intelligenz ist, bildet das Deep Learning, das künstliche neuronale Netze nach dem Vorbild des menschlichen Gehirns bezeichnet, denen aber bis dato sowie auf absehbare Zeit die Vielseitigkeit und Flexibilität menschlicher Intelligenz fehlt.
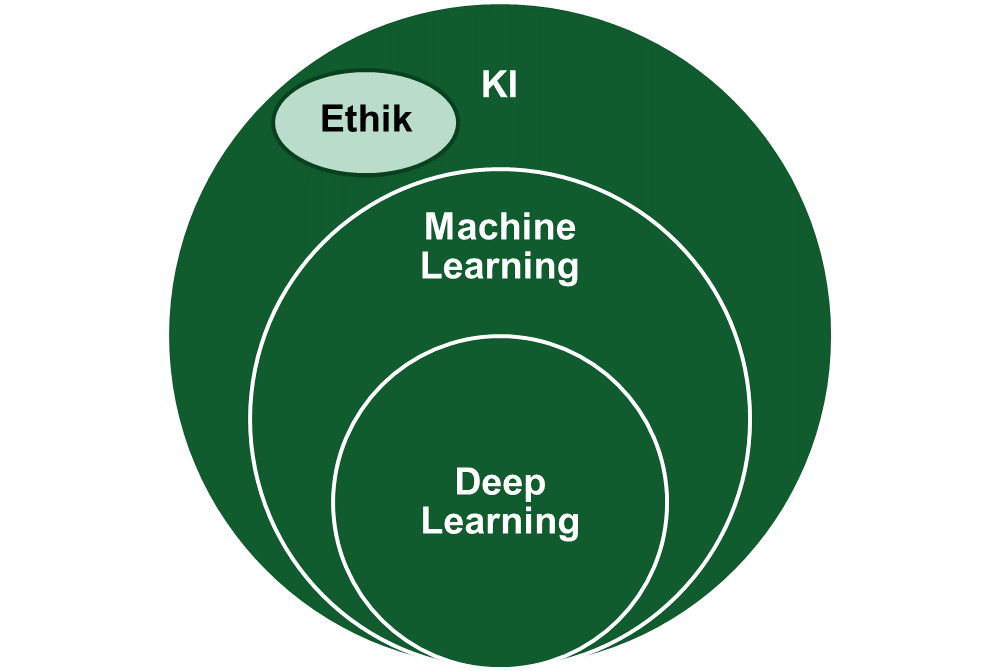
Abbildung 1: Maschinelles Lernen und neuronale Netze als besondere (und derzeit populäre) Ausprägungen von KI, die als Forschungsfeld daneben noch u.a. angewandte Ethik, also Ethik der Algorithmen beinhaltet, die sich u.a. mit der Verzerrung von Daten und fehlenden Erklärbarkeit von Algorithmen befasst.
Die Leistungsfähigkeit neuronaler Netzwerke ist überbewertet
Durch die Nachahmung der Struktur menschlicher Gehirne durch neuronale Netze suggeriert Deep Learning, dass Menschen ihre Intelligenz rein durch Beobachtungen aufbauen, darüber, was rund um sie herum passiert; und dass Maschinen dies ebenso vollziehen können. Der Sprachwissenschaftler und Philosoph Noam Chomsky hat uns hingegen gelehrt,[1] dass Menschen mit einer Veranlagung zu lernen geboren werden, programmiert dazu, Sprache zu beherrschen und die physikalische Welt zu verstehen. Anders als neuronale Netze sind wir nicht so datenhungrig und müssen nicht eine Millionen Orangen gesehen haben, um eine zu erkennen. Wir können sogar verallgemeinern: Wenn Kinder wissen, was eine Orange ist, können sie folgern, dass eine Mandarine eine Art Orange ist; wohingegen neuronale Netze jedes Mal, wenn wir sie einen neuen Typ eines Dings erkennen lassen wollen, mit dem Training wieder von vorne anfangen müssen. Wir Menschen können darüber hinaus kontrafaktische Überlegungen anstellen. Google Translate kann zwar das französische Gegenstück zu dem deutschen Satz „Die Orange wurde gedrückt, und deshalb lief der Saft heraus“ bilden. Aber das Programm hat keine Ahnung, was die Wörter bedeuten. Und somit könnte es nicht sagen, was mit der Orange passiert wäre, wenn sie nicht gedrückt worden wäre. Menschen erfassen nicht bloß grammatikalische Regeln und Muster, sondern auch Semantik und die Logik hinter Regeln und Mustern. Man könnte einem Kind beispielsweise im Französischunterricht das nicht-existierende Verb „plumrer“ vorlegen und es könnte vermutlich in der Lage sein, das Partizip „plumré“ abzuleiten. Natürlich hat es das Verb noch nie gesehen, wurde damit nicht „trainiert“. Es hat lediglich eine Logik, wie Sprache funktioniert, erfasst und auf eine neue Situation angewendet. Unsere heutigen Deep Learning Systeme sind demgegenüber nicht in der Lage, abstraktes Wissen zu integrieren. Ohne weiterführende neue Ansätze mag Deep Learning solche Limitationen künftig nicht überwinden.
Neuere Entwicklungen in der KI
Drei wichtige Forschungsstränge könnten KI, eventuell gar über den derzeit populären Zweig des DL, mittel- bis langfristig zur moralfähigen reifen lassen, da sie Verständnisbegabungen nachbilden.
Erstens werden wir in Zukunft mehr Top-Down-Systeme vorfinden, die nicht so viele Daten benötigen und schneller, flexibler und, wie der Mensch, intelligenter sind. Eine Reihe von Unternehmen und Organisationen setzen diese natürlicheren Systeme bereits ein.
So sortieren Menschen routinemäßig und oft mühelos Wahrscheinlichkeiten und handeln dem jeweiligen Ranking entsprechend, selbst mit relativ wenig Vorerfahrung. So packen wir vor dem Spaziergang ohne viel Kopfzerbrechen einen Regenschirm ein, wenn der Blick aus dem Fenster auf dunkle, tiefhängende Wolken trifft. Maschinen werden nun gelehrt, diese Vorgehensweise durch die Anwendung von sogenannten Gaußschen Prozessen (benannt nach dem großen Mathematiker Carl Friedrich Gauß), also spezielle wahrscheinlichkeitstheoretische Prozesse, nachzuahmen – wahrscheinlichkeitsbasierte Modelle nämlich, die mit großer Unsicherheit umgehen, auf spärliche Daten reagieren und aus Erfahrungen lernen können. Solche Gaußschen Prozesse sind vielversprechend. Sie benötigen keine großen Datenmengen, um Muster zu erkennen; die Berechnungen, die für Inferenz (logische Ableitungen), und Lernen erforderlich sind, gestalten sich relativ einfach, und falls etwas schiefgeht, kann die Ursache verfolgt werden, im Gegensatz zu den limitierten neuronalen Netzen.
Zweitens müssen die Verfahren des DL keineswegs aufgegeben werden. Oren Etzioni vom Allen Institute tritt etwa für „gesunden Menschenverstand“ in Maschinen ein, indem er ihnen beibringt, wie sie beispielsweise Alltagsgegenstände und -handlungen zu verstehen haben, wie natürliche Kommunikation aussieht, wie sie mit unvorhergesehenen Situationen umzugehen hätten. Was aber für den Menschen ohne explizite Schulung oder Daten natürlich ist, erweist sich für Maschinen abermals als teuflisch schwierig. Kein derzeit eingesetztes KI-System kann eine Vielzahl einfacher Fragen zuverlässig beantworten, wie: “Wenn ich meine Bücher in eine Box stecke, sind sie dann auch morgen noch da drin?” oder “Woher wissen wir, ob eine Weinflasche voll ist?”.
Daran Anstoß nehmend haben Forscher von Microsoft und der McGill University gemeinsam ein System entwickelt, das vielversprechend ist, um Mehrdeutigkeiten in der natürlichen Sprache zu entwirren; ein Problem, das verschiedene Formen von Inferenz und Wissen erfordert.
Und schließlich drittens sollten wir eine Lanze für kausale Modellierung brechen. IBM Research zufolge etwa wird Kausalität zunehmend Korrelationen dort ersetzen: Jeder weiß, dass das Krähen des Hahnes im Morgengrauen die Sonne nicht “aufstehen” lässt und dass umgekehrt das Betätigen eines Schalters das Einschalten eines Lichts bewirkt. Während solche Intuitionen über die kausale Struktur der Welt integraler Bestandteil unseres täglichen Handelns und Urteilens sind, basieren die meisten unserer heutigen KI-Methoden grundsätzlich auf einfacheren statistischen Zusammenhängen und haben kein tiefes „Verständnis“ von Ursache-Wirkungs-Zusammenhängen. Aufkommende kausale Inferenzmethoden erlauben es uns dagegen, aus Daten kausale Strukturen abzuleiten, Interventionen effizient auszuwählen, um vermeintliche kausale Zusammenhänge zu testen und bessere Entscheidungen zu treffen, indem wir das Wissen über die kausale Struktur nutzen. Somit können wir für 2019 kausale Modellierungstechniken als zentrale bahnbrechende Neuerung auf dem Tableau der KI ausmachen.[2]
Zwischenfazit: KI als “unsere nächsten Verwandten”?
Andere wichtige neue Forschungsstränge wie Paare von neuronalen Netzen, die sich gegenseitig trainieren und herausfordern (was das Massendatenproblem entschärft), existieren. Aber eines sollten wir bei den ganzen Ambitionen, KI menschenähnlicher zu machen, um sie sich in unserer Welt navigieren zu lassen, nicht vergessen: Ist es wirklich nützlich oder wünschenswert, eine getreue Nachbildung menschlicher Denkstile anzustreben? Es gibt bereits „Maschinen“ (L’homme machine (1748), gemäß des französischen Aufklärers Julien Offray de La Mettrie), die wie Menschen denken können. Vielleicht liegt der Wert von KI, die derzeit lediglich Tools sind, darin, dass sie verschieden von uns, „rationaler“ als wir sind. Komplementarität sollte vielleicht auch für die weiteren Entwicklungsschritte taktgebend und die Wahrung einer gewissen nichtmenschlichen Form der Intelligenz geboten sein.
Moralfähigkeit der KI?
Was hingegen die Frage nach dem moralischen Status von KI angeht, so kann sie zumindest jetzt vor der Ausreifung obiger und weiterer Innovationen eindeutig beantwortet werden: Wie schon an anderer Stelle dargelegt setzt „Ethik in KI“ oder, präziser gesprochen, die Anerkennung von KI als moralischer Akteur respektive Verantwortungsübernahme oder –zuschreibung durch die KI Verständnisgabe aufseiten derselben voraus. Und die Annahme einer Verständnisgabe in oder von Verantwortungsübernahme oder –zuschreibung durch heutige KI ist nicht legitim: Um beim Beispiel der Orange zu bleiben, das DL-System mag zwar imstande sein, Sätze darüber ins Französische zu übersetzen, aber es die Bedeutung der Wörter darin zu erkennen, überfordert sie. Anderenfalls wären Maschinen auch drauf und dran, den Turing Test zu bestehen, der klassischerweise als zentraler Prüfstein für wirkliche künstliche Intelligenz gesetzt wird.[3]
Somit ist zumindest klar: Genau wie ein Hammer oder ein Hund (der wohlbemerkt kein Tool ist) zwar die Ursache für ein Ereignis (zum Beispiel beschädigtes Eigentum) sein kann, aber nur der Hersteller, der Anbieter oder Anwender für die Kosten des Schadens verantwortlich, so gilt Analoges für KI. In ihrer absehbaren Form beim „autonomen“ Fahren (Uber), bei Objekterkennung (Autos auf Bildern), bei Textanalyse (Google Translate) oder numerischer Analyse (Syntherion) bleibt sie ziemlich dumm und wir wiederum sind schlecht beraten, wenn wir ihre Fähigkeiten überschätzen, sie mit Akteuren verwechseln oder solchen KIs Autonomie einräumen. Für die Zeit nicht nur graduell höherentwickelter KI, die noch nicht greifbar scheint, wobei jedoch wesentliche Meilensteine hierfür skizziert sind, lohnt es sich, nicht zuletzt juristisch, die Frage nach Moral in KI neu zu adressieren.
[1] Chomsky, N. 2006. Language and Mind. 3rd edition. Cambridge, MA: Cambridge University Press.
[2] Pearl, J. 2018. The Book of Why: The New Science of Cause and Effect. NYC: Basic Books.
[3] Turing, A.M. 1950. Computing Machinery and Intelligence. Mind, 59: 433–460.
Dieser Artikel ist lizenziert unter einer Creative Commons Namensnennung 4.0 International Lizenz.

Kommentar schreiben