The Wikimedia Foundation wants to create a knowledge platform that goes beyond encyclopedia entries. It wants to achieve that goal using bots and similar technologies. But what role will human authors play?
While Wikipedia has been stagnating in many areas for years, its sister project Wikidata has been gaining speed. As it celebrated its fifth birthday, the latter platform offered users information on 37 million different data objects. Almost one contribution in three to Wikimedia sites can be found in Wikidata. Yet the project is largely unknown to the general public.
That could change. In a strategy paper, the Wikimedia Foundation has sketched out a future in which Wikipedia is only part of the overall project: “By 2030, Wikimedia will become the essential infrastructure of the ecosystem of free knowledge, and anyone who shares our vision will be able to join us.” In this future, humans alone will not be laying the groundwork; they will be joined by machines: “Our collective success is made possible by people and powered by technology. It is how we document and understand our world together.”
More than just book knowledge
In other words, Wikipedia’s organizers want to explore new technologies which they can use to archive knowledge and assemble it for others – whether those technologies be Wikipedia articles or a question-and-answer machine that hones in on exactly the information a user is looking for at any particular moment.
Wikidata is one of the pillars supporting this undertaking. The site does not collect global knowledge as articles, but as structured data. Instead of listing a long article on the life and work of British writer Douglas Adams, the object “Douglas Adams” – also known as Q42 – is created and multiple characteristics assigned to it, for example his date of birth, date of death and the books he wrote, not to mention any relevant Wikipedia entries and public databases containing additional information about him.
The assembled data also reveal shortcomings in previous Wikipedia efforts. An examination of the stored information has shown, for example, that the encyclopedia contains relatively few articles about women in modern history. A Wikidata project group has been formed to identify these problems and fix them by creating and updating articles and Wikidata entries about women. The goal is to prevent human biasBias In der KI bezieht sich Bias auf Verzerrungen in Modellen oder Datensätzen. Es gibt zwei Arten: Ethischer Bias: systematische Voreingenommenheit, die zu unfairen oder diskriminierenden Ergebnissen führt, basierend auf Faktoren wie Geschlecht, Ethnie oder Alter. Mathematischer Bias: eine technische Abweichung in statistischen Modellen, die zu Ungenauigkeiten führen kann, aber nicht notwendigerweise ethische Probleme verursacht. from infiltrating the data structure of Wikidata and other platforms.
When a virtual assistant like Amazon’s Alexa or Google Home responds to a general question, chances are good that the answer already comes from Wikipedia. In the future, thanks to Wikidata, the knowledge available in Wikipedia will appear in more and more places, since the database is directly machine-readable, while the information inscribed in the encyclopedia is more like buried treasure and must be analyzed using a variety of text-recognition technologies.
“Wikidata’s impact is perhaps even more significant outside of the Wikimedia universe,” writes author and researcher Andrew Lih. For example, national libraries and museums have already linked their catalogues to Wikidata. The advantage for these institutions is that their knowledge is made available to the public and they can offer their own visitors more information. Data comparisons, moreover, can increase accuracy: If an author or artist cannot be found in Wikidata, then possibly the name is spelled incorrectly in the institution’s catalogue. This is turning Wikidata into a central interface for numerous databases covering a wide range of the world’s knowledge.
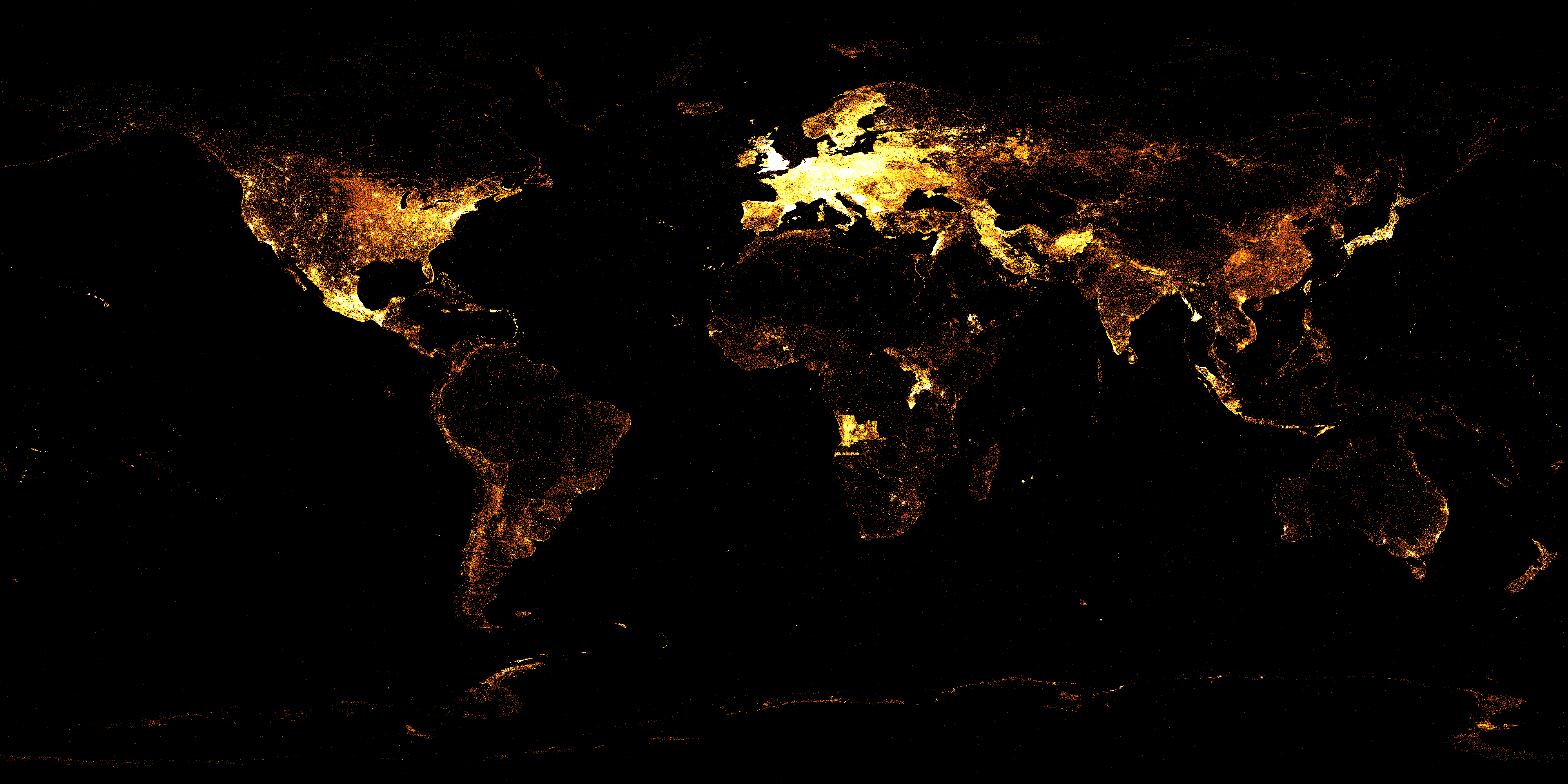
The graphic representation of Wikidata-entries shows, which parts of the world are already well covered and where black patches prevail. (Source: Wikimedia.org)
Bots expand the Cebuano Wikipedia
Not only is Wikidata machine-readable, bots are handling a large part of the writing done for the platform. For instance, if a geographical databank or a bibliographic catalogue with thousands or even millions of entries needs to be imported into Wikidata, algorithms identify the correct Wikidata objects and add the relevant information on their own. Humans are still needed, however, for quality assurance and as decision makers if the various data do not match.
The Bot-Wikipedia
In principle, bots could take care of most of the work required for the Wikipedia versions that do not have communities as large as those using the English or German versions. If a Wikidata object has enough statements stored in it, a bot can use them to compose a text that at least looks like a Wikipedia article.
A Wikipedia written solely by bots is anything but a far fetched fantasy. While only 10 percent of all entries in the German and English Wikipedias are composed by bots, the percentage is considerably higher for less common language editions. The leader is the Wikipedia version written in Cebuano, a language spoken in the Philippines. The Cebuano encyclopedia is almost completely the result of bot activity.
Thanks to the extensive work of bots, the Cebuano Wikipedia surpassed the German platform regarding numer of articles. With more than 5 million articles Cebuano Wikipedia is now the second largest Wikipedia version worldwide.
One automated assistant that has been particularly diligent is Lsjbot, programmed by Swedish Wikipedia author Lars Sverker Johansson. Day in and day out for years, the bot has written thousands of articles based on database entries of all sorts. Thanks to its efforts, the Cebuano Wikipedia contains mini-articles about even the smallest towns in Germany and the rarest of animals. The result is that the version for Cebuano readers has over five million articles, making it the second largest edition worldwide. The Wikipedia community, however, continues to debate whether the texts, created using simple templates, are actually useful knowledge and whether they really benefit the project.
![]()
The profile picture of the “Lsjbot”
Conflict over conveyor-belt bots
Supporters of automatically created articles argue that the information which is assembled is always valuable and should therefore be made available to readers of the various Wikipedia versions. People who subscribe to this line of thought also believe that if an article already exists, it will encourage readers to become authors themselves.
Critics maintain that knowledge always needs a context, one that should be developed by the appropriate Wikipedia community. For example, it is frowned upon in most Wikipedia communities to simply translate an article from another Wikipedia version. For Wikipedians, the encyclopedia itself is not sufficient as a source of information. Moreover, critics fear that automatically generated entries discourage potential authors from contributing, since anyone who sees that an article already exists on a given subject will not have much reason to begin writing one from scratch.
Bots should inspire human authors
The Wikimedia Foundation maintains a neutral position on this issue, feeling that the members of a community must decide for themselves which bots are used. The organization is searching for a happy medium: “Generally, we aim to develop technology, including algorithms and AI, to better support human editors on Wikipedia.”, explains Aaron Halfaker, who carries out research for the Wikimedia Foundation on a number of subjects, including the use of neuronal networks.
The Wikimedia Foundation has therefore created an interface that gives authors tips on where their work will do the most good. The neuronal network that provides the vandalism-fighting assistant ClouBot NG with information on inappropriate entries also evaluates the quality of the encyclopedia’s articles in order to identify the spots that need the most attention. Instead of merely rejecting what certain authors have contributed, the algorithms have also been tasked with motivating contributors to produce better results.
Neuronal network imitates human Wikipedia authors
Another suggested compromise is the so-called ArticlePlaceholder, which is activated most often in smaller Wikipedia editions. If a reader in Tirana, for example, wants to know about a certain subject that is not yet in the Albanian Wikipedia but present in other editions, then the relevant information is presented as a table based on what is available in Wikidata. The reader thus finds the information he or she is looking for in a form that cannot be confused with an article written by a human being.
For some people, however, that is not enough. That is why a small team of researchers from the universities in Southampton and Lyon is working on translating Wikidata information into natural-sounding language using a neuronal network. Instead of deploying set templates like Lsjbot, the new project includes work previously done by human authors.
“This model learns from Wikidata facts and their existing Wikipedia articles in the respective language ,” explains Lucie-Aimée Kaffee, speaking with blogs.bertelsmann-stiftung.de/algorithmenethik. The first tests in Esperanto and Arabic have shown that this method produces better results than machine-based translations of English articles.
“Not in our lifetime”
This project is needed, Kaffee says, because of how long it is taking to expand the various language versions. “For example, an article such as ‘German residence permit’ exists on Wikipedia in only three languages: English, German and Russian,” she says. Such permits help foreigners in Germany and the European Union prove they have a right to be there. Information on the permits is lacking, however, in the languages spoken by the main groups immigrating to Europe.
Halfaker is skeptical that the method being developed by the researchers will actually prove capable of generating adequate articles. “ I think there’s quite a large niche for automated text generators for “placeholders” and maybe even article-starters or gap-finders that will aid editors in writing and maintaining articles” he explains.
Ultimately, the Wikimedia researcher feels, algorithms are not up to producing quality content. “Algorithms will not replace human editors on Wikipedia in our lifetime,” he says.
If you want to know more about the cooperation between bots and human editors in Wikipedia, read Part1 or Part 2 of our series. Subscribe to our RSS feed or e-mail newsletter to find out when new posts are added to this blog.

{kind=link}
Write a comment